Python basics: classes
This is the post version of a talk I had the opportunity to give to my collegues at CAPSiDE-NTT. It is actually a follow up from another talk that also became a blog post here.
In certain sense, this is also an apology: I gave this talk trough some nasty videoconference tool because we were all in our homes due to the confinment. In that scenario I only had my voice and a single screen at my disposal to try to transmit some information to the patient audience.
How not to give a remote talk
So I decided to share my screen, opened a terminal and started Emacs. (I couln’t have missed that opportunity, of course.)
$ tmux
$ TERM=xterm-256color emacs -nwDuring the following hour, I talked and live coded, and wrote the relevant points and code on respective Emacs buffers. I also had room for a terminal shell at the right.
The setup looked something like his:
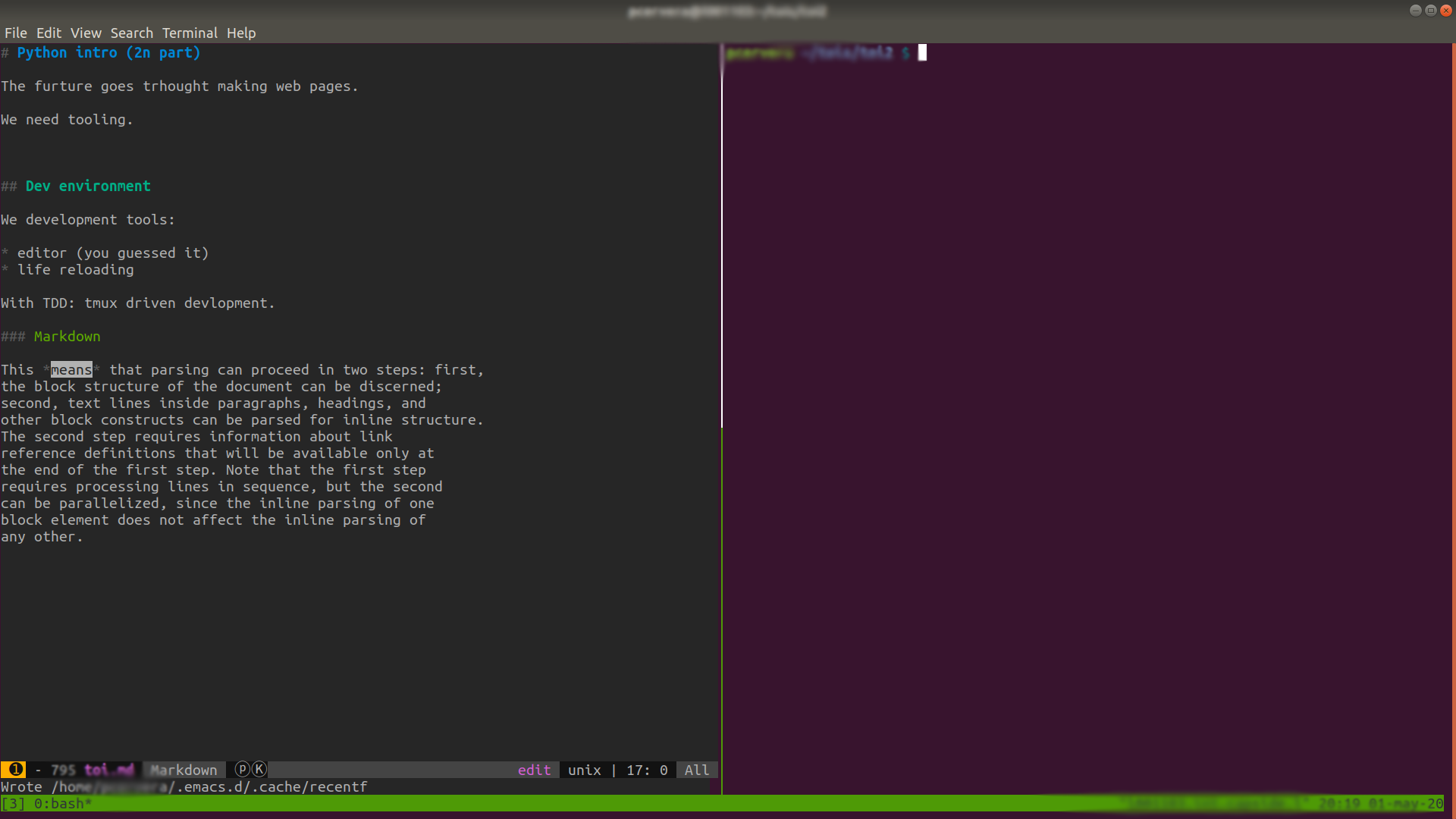
The whole session was a little odd.
I felt like being alone in a porch with an amateur radio station trying to comunicate with other civilizations. You know you’ve sent a message. You think it will arrive. You hope it will be decoded properly. But then, the only think you can really do is wait an see if it is interpreted correctly, not taken into an explicit war delcaration and wish that the aliens do not think, Hey, there’s some kind of spicy food down there, my sweet heptapodie.
But I disgress.
The future goes trough making web pages (again)
On the last post we saw some way to write web pages. It was an excuse to present python functions.
>>> from paudirac.html import html, body, p
>>> html(
... body(
... p('ola ke ase', _class='blink'),
... )
... )
'<html><body><p class="blink">ola ke ase</p></body></html>'It is ovious that writing web pages by hand via function calls is crazy. Or it is not?. Anyway, there are other ways to write web pages. One that is particularly human friendly is Markdown.
Markdown
Markdown is intended to be readable as is, like plain text email. Some typical markdown document (source.md) looks like:
# Python intro (2n part)
The furture goes trhought making web pages.
We need tooling.
## Dev environment
We development tools:
* editor (you guessed it)
* life reloadingAnd is know to be transformed to some html like
<html>
<body>
<h1>Python intro (2n part)</h1>
<p>The furture goes trhought making web pages.</p>
<p>We need tooling.</p>
<h2>Dev environment</h2>
<p>We development tools:</p>
<ul>
<li>editor (you guessed it)</li>
<li>life reloading</li>
</ul>
</body>
</html>We just need a tool that transforms the markdown to html. We will call this tool m and this is what we will be constructing in the rest of this post.
But, in order to do so, we need a proper development setup and methodology, and this means TDD.
Life reloading
This was a typo I made during the talk, but, given the current weird situation we are facing, I thought it was actually more accurate than the _live reloading_ needs we have in development environments.TDD
What is a proper development setup? A proper development setup is one wich allows you to interact with the code (like a REPL), or at least see the effect of the changes ASAP.
Test Driven Development is a well known way to build trust and assert that things are going like you think they will.
The basic methodology is to start with a failing test. Then you write the smallest amount of code to make the test pass. If you do this diligently, then you build enough trust that the code is doing what it should be doing.
But I think TDD is realy hard. You have to be strict and always play by the TDD rules if you want to build trust. This is something that in a real project needs support, agreement and commitment from developers, managers and even the whole company.
But if you are exploring by yourself and your main objective is to gain knowledge, you need a system you can play with. You want fast cycles not to be productive, but to see how the system works and responds.
Actually, there are languages, or environments that give you this from the start. Python comes with a REPL, but we need something better.
Enter TDD.
TDD: Tmux Driven Development
So, we want to build a system to transform our markdown source document to html. And we said we will call this utility m.
We will do it in small steps. First, create an executable python script and call it m:
#!/usr/bin/env python3
import sys
sys.stdout.write(sys.stdin.read())The only thing this script does is reading from stdin and writting to stdout, look:
$ chmod +x m
$ ./m << EOF
> this does almost nothing
> EOF
this does almost nothingWe can call it a day, right?
We can do better. Here tmux comes in. We split the window in two. In one of the panes m continuously transforms our source.md file to a dest.html file:
$ while [ true ]; do
> cat source.md | ./m > dest.html
> sleep 1;
> echo -n '.';
> done
.....On the other, we will be watching the results:
$ watch cat dest.htmlThe whole setup will look something like this
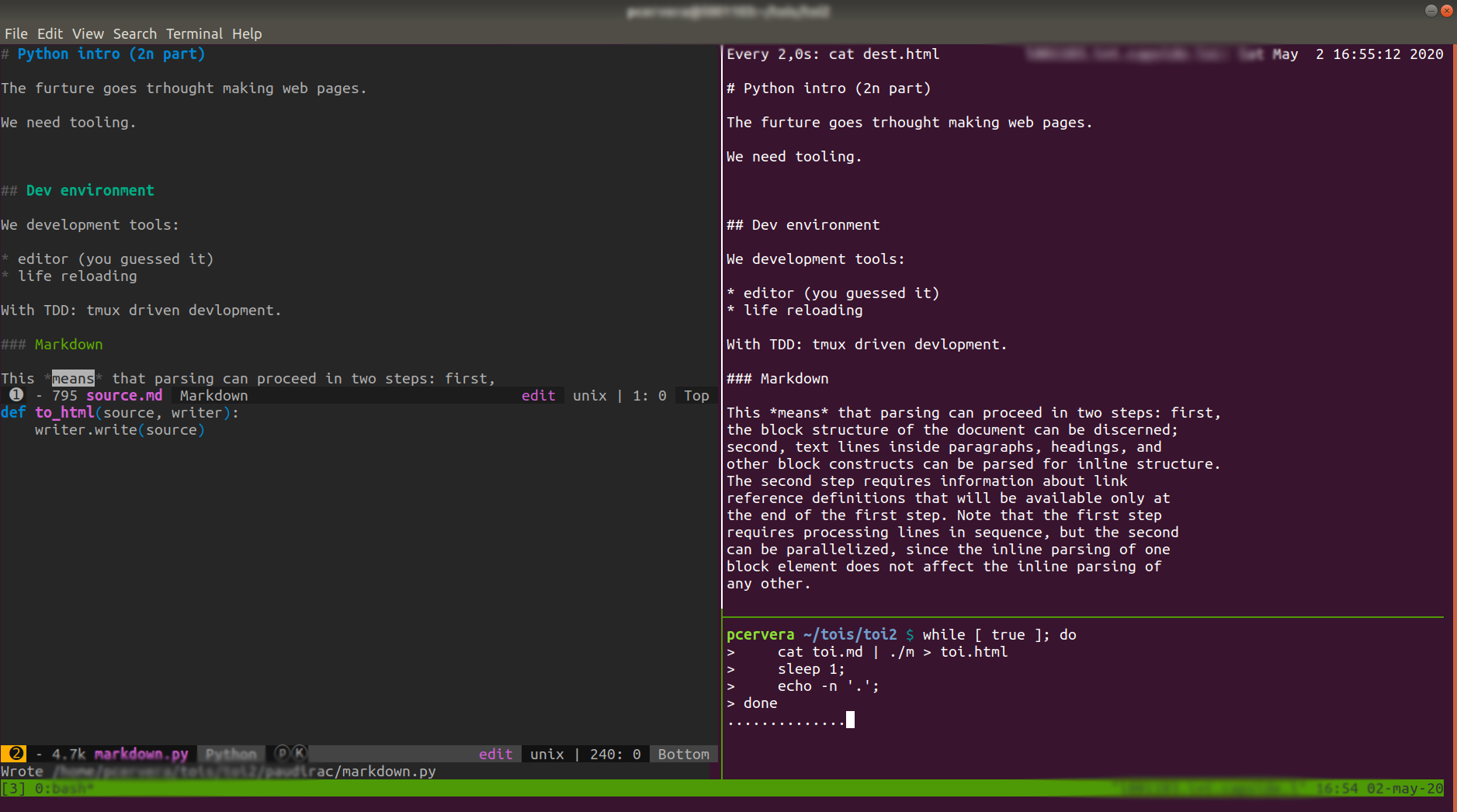
We just need to a bit more plumbing
$ mkdir paudirac
$ touch paudirac/__init__.py
$ touch paudirac/markdown.pydefine an initial `to_html` function inside the `paudirac.markdown` module
def to_html(source, writer):
writer.write(source)and change m to read like this
#!/usr/bin/env python3
import sys
from paudirac.markdown import to_html
to_html(sys.stdin.read(), writer=sys.stdout)From this point on, the whole system is running and everything is plumbed: when we change the source.md, dest.html will automatically be rebuilt.
How cool is that?!
Block structure
Well, actually, rigth now, the system is not specially cool. I mean, the work done by to_html amounts to nothing at all. But, like in TDD (here I meant Test Driven Development), the interface has driven our (now spartan) implementation.
Let’s get our hands dirty now.
From the CommonMark spec (a Markdown flavor) we got the first insight
This means that parsing can proceed in two steps: first, the block structure of the document can be discerned; second, text lines inside paragraphs, headings, and other block constructs can be parsed for inline structure. The second step requires information about link reference definitions that will be available only at the end of the first step. Note that the first step requires processing lines in sequence, but the second can be parallelized, since the inline parsing of one block element does not affect the inline parsing of any other.
—CommonMark spec
And the separator of blocks are blank lines.
So, we have to make a decision: how to start to process the source files. There are lots of choices: characters, words, etc.
It seems reasonable to start in a fairly large level of abstraction: lines.
![[source] -> [process lines] -> [list of lines]](./lines.svg)
We define a lines generator that does that:
def lines(source):
for line in source.split('\n'):
yield line + '\n'and modify the to_html to use that one
def to_html(source, writer):
lns = lines(source)
writer.write(lns)This results in
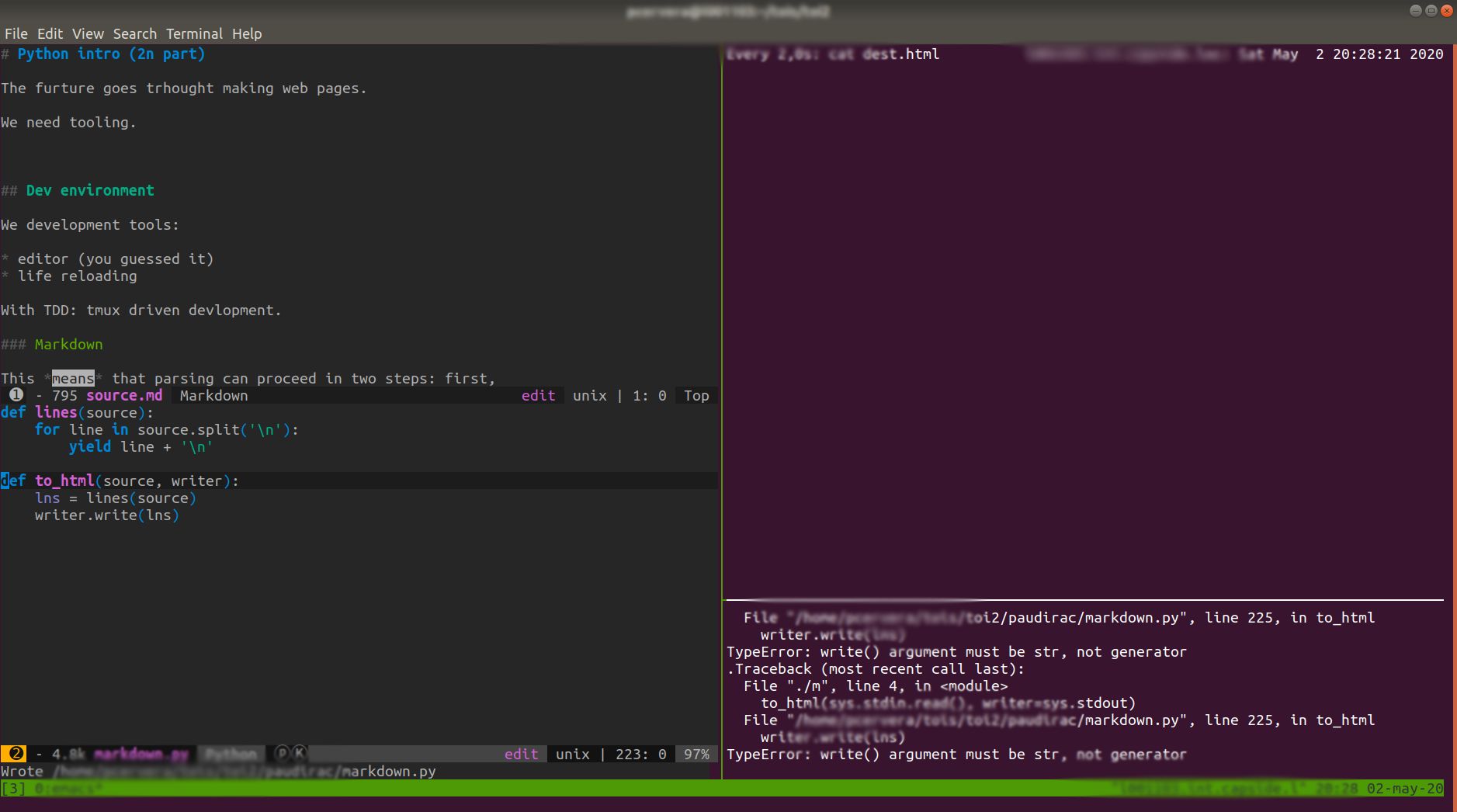
so you can see that in this setup, tmxu is also acting as a fairly nice debugger! How cool is that?!
Okay, we have to pass a string to the writer
import pprint
def to_html(source, writer):
lns = lines(source)
lns = list(lns)
writer.write(pprint.pformat(lns))(Note that we are forcing the lns generator to become a list in order to be printable.)
This produces something like (fragment):
['# Python intro (2n part)\n',
'\n',
'The furture goes trhought making web pages.\n',
' \n',
'We need tooling.\n',
' \n',
' \n',
'\n',
'## Dev environment\n',Now that we have the lines, we aim for the blocks. In markdown, the newline character \n doesn’t mean anything special. Actually, two contiguous non-blank lines contain text that is from the same block.
![[lines]-> [proccess blocks] -> [blocks]](./blocks.svg)
What separates blocks from one another are blank lines. We create an axuxiliary function that tells us if a line is blank or not:
import re
_IS_BLANK = re.compile(r'\s+')
def is_blank(line):
return _IS_BLANK.match(line)and with it, we can define the blocks function:
def blocks(lns):
buffer = []
for line in lns:
if is_blank(line):
if len(buffer):
yield buffer
buffer = []
else:
buffer.append(line)
if len(buffer):
yield bufferand redefine our to_html
def to_html(source, writer):
lns = lines(source)
blks = blocks(lns)
blks = list(blks)
writer.write(pprint.pformat(blks))This actually gives us all the block structure!
[['# Python intro (2n part)\n'],
['The furture goes trhought making web pages.\n'],
['We need tooling.\n'],
['## Dev environment\n'],
['We development tools:\n'],
['* editor (you guessed it)\n', '* life reloading\n'],
['With TDD: tmux driven devlopment.\n'],
['### Markdown\n'],
['This *means* that parsing can proceed in two steps: first, \n',
'the block structure of the document can be discerned; \n',
'second, text lines inside paragraphs, headings, and \n',
'other block constructs can be parsed for inline structure. \n',
'The second step requires information about link \n',
'reference definitions that will be available only at \n',
'the end of the first step. Note that the first step \n',
'requires processing lines in sequence, but the second \n',
'can be parallelized, since the inline parsing of one \n',
'block element does not affect the inline parsing of \n',
'any other.\n']]The classical way to give structure to structure
We no longer have a plain file. We first transformed that to a list of lines, and now we have a list of lists of lines. Also, we’ve got rid off the blank lines, that were only needed for the block structure.
As the spec said, now we only have to start working on the content of the blocks themselves.
At this point, tough, I think things will be easier if we add a little bit of structure, and modeling.
Actually, we have identified some kind of object in our model. But it is on our minds. And our minds are like RAM and not always are a shared resource.
There is a way to make models explicit, exact and out of our minds: source code.
We are talking about Blocks. Let’s introduce a model for that.
Python has nice support for object modeling: classes.
A simple class in python is defined like this:
class Block:
def __init__(self, contents):
self.contents = contentsAnd with that in place, we can change our blocks function to return, you’ve guessed it, Blocks:
def blocks(lns):
buffer = []
for line in lns:
if is_blank(line):
if len(buffer):
yield Block(contents=buffer)
buffer = []
else:
buffer.append(line)
if len(buffer):
yield Block(contents=buffer)With that, our screen now looks not so promising, tough:
[<paudirac.markdown.Block object at 0x7fcb1807c438>,
<paudirac.markdown.Block object at 0x7fcb1807d898>,
<paudirac.markdown.Block object at 0x7fcb1807d978>,
<paudirac.markdown.Block object at 0x7fcb1807d780>,
<paudirac.markdown.Block object at 0x7fcb180ae940>,
<paudirac.markdown.Block object at 0x7fcb180ae978>,
<paudirac.markdown.Block object at 0x7fcb180aea20>,
<paudirac.markdown.Block object at 0x7fcb180bbf28>,
<paudirac.markdown.Block object at 0x7fcb180bbf60>]What’s happening here is that python is printing the Block object with its default internal representation. Fortunately, we can override that default implemetation:
class Block:
def __init__(self, contents):
self.contents = contents
def __repr__(self):
return f'Block(contents={pprint.pformat(self.contents)})'which gives us a much better result, right?
[Block(contents=['# Python intro (2n part)\n']),
Block(contents=['The furture goes trhought making web pages.\n']),
Block(contents=['We need tooling.\n']),
Block(contents=['## Dev environment\n']),
Block(contents=['We development tools:\n']),
Block(contents=['* editor (you guessed it)\n', '* life reloading\n']),
Block(contents=['With TDD: tmux driven devlopment.\n']),
Block(contents=['### Markdown\n']),
Block(contents=['This *means* that parsing can proceed in two steps: first, \n',
'the block structure of the document can be discerned; \n',
'second, text lines inside paragraphs, headings, and \n',
'other block constructs can be parsed for inline structure. \n',
'The second step requires information about link \n',
'reference definitions that will be available only at \n',
'the end of the first step. Note that the first step \n',
'requires processing lines in sequence, but the second \n',
'can be parallelized, since the inline parsing of one \n',
'block element does not affect the inline parsing of \n',
'any other.\n'])]Dunder methods
I think that your intuition is helping to understand here. In some sense, you’ve guessed that __init__ is some kind of constructor method and __repr__ is some kind of toString method. But, depending on your mileage, your intuition could vary.
Actually both __init__ and __repr__ are special python methods.
Like most things in python, they are special by convention. There is no hard rule that forbids you to create a class with a method named __bar__.
>>> class Foo:
... def __bar__(self):
... return 'baz'
...
>>> f = Foo()
>>> f.__bar__()
'baz'but it will be extremely unpythonic!
The convention here is that method names that have two leading underscores and two trailing underscores, are used by the interpreter for some special circumstances.
Because it is difficult to say underscore underscore init underscore underscore, the community agreed to call all the methods that follow that convention dunder methods, and you can talk about dunderinit or dunderrepr and everybody will understand, except your closest friends.
Divide and conquer
At this point, and following the spec advice, we can start working on the blocks themselves. Any block has all the information it needs.
In this simple source.md example whe can see at least 3 types of blocks
- headings,
- paragraphs and
- lists
Headings
We identify heading because their contents start with a # character. As before, we create a helper method to filter the headers out. Regexes at our rescue again:
_IS_H = re.compile(r'^#+')
def is_h(text):
return _IS_H.match(text)We create a class H to hold the text of this special kind of block:
class H:
def __init__(self, text):
self.text = text
def __repr__(self):
return f'H(text="{self.text}")'and another generator function parse that, given some blocks, will return us some representation of html, at this point a sequence of Hs and Blocks:
def parse(blks):
for blk in blks:
if len(blk.contents) == 1 and is_h(blk.contents[0]):
yield H(text=blk.contents[0])
else:
yield blkWe glue it toghether in our to_html function:
def to_html(source, writer):
lns = lines(source)
blks = blocks(lns)
html = parse(blks)
html = list(html)
writer.write(pprint.pformat(html))That results in this output:
[H(text="# Python intro (2n part)
"),
Block(contents=['The furture goes trhought making web pages.\n']),
Block(contents=['We need tooling.\n']),
H(text="## Dev environment
"),
Block(contents=['We development tools:\n']),
Block(contents=['* editor (you guessed it)\n', '* life reloading\n']),
Block(contents=['With TDD: tmux driven devlopment.\n']),
H(text="### Markdown
"),
Block(contents=['This *means* that parsing can proceed in two steps: first, \n',
'the block structure of the document can be discerned; \n',
'second, text lines inside paragraphs, headings, and \n',
'other block constructs can be parsed for inline structure. \n',
'The second step requires information about link \n',
'reference definitions that will be available only at \n',
'the end of the first step. Note that the first step \n',
'requires processing lines in sequence, but the second \n',
'can be parallelized, since the inline parsing of one \n',
'block element does not affect the inline parsing of \n',
'any other.\n'])]Not bad.
But we can work now on the details.
Information hiding
The parse function is a little bit ugly. There’s too much logic in there. There’s too much detail. As we’ve said, we wanted the parse function to bee feed with blocks and to give back html. But looking at it, it speaks about weird things like content[0]. Those trees don’t let us see the forest.
We can easily refactor those details to a block method. We can ask the block itself
class Block:
def __init__(self, contents):
self.contents = contents
def __repr__(self):
return f'Block(contents={pprint.pformat(self.contents)})'
def is_h(self):
return len(self.contents) == 1 and _IS_H.match(self.contents[0])and make the parse function clearer
def parse(blks):
for blk in blks:
if blk.is_h():
yield H(text=blk.contents[0])
else:
yield blkAlso, we can move the details of how to make an instance of an H to the H class himself.
Python doesn’t provide constructor method overloading, but we can use the named constructor pattern (which is a special case of factory method) and create a special constructor to creat an H from a block.
class H:
def __init__(self, text):
self.text = text
def __repr__(self):
return f'H(text="{self.text}")'
@classmethod
def from_block(cls, blk):
contents = blk.contents[0]
return cls(text=contents)The parse function now already expresses what it does without exposing how it does it
def parse(blks):
for blk in blks:
if blk.is_h():
yield H.from_block(blk)
else:
yield blkThis is super nice, because now we can work with the H class, and refine its responsabilities, without touching any other code.
class H:
def __init__(self, level, text):
self.level = level
self.text = text
def __repr__(self):
return f'H(level={self.level}, text="{self.text}")'
@classmethod
def from_block(cls, blk):
contents = blk.contents[0]
m = _IS_H.match(contents)
if not m:
raise ValueError(f'Block {blk} is not a valid H block')
_, end = m.span()
text = contents[end:-1].strip()
return cls(level=end, text=text)Note that we’ve actually been able to change the class definition and modify even the initializer, and this had no effect on the working code other that creating a richer H object.
The extra cost of creating a named constructor is already paying.
[H(level=1, text="Python intro (2n part)"),
Block(contents=['The furture goes trhought making web pages.\n']),
Block(contents=['We need tooling.\n']),
H(level=2, text="Dev environment"),
Block(contents=['We development tools:\n']),
Block(contents=['* editor (you guessed it)\n', '* life reloading\n']),
Block(contents=['With TDD: tmux driven devlopment.\n']),
H(level=3, text="Markdown"),
Block(contents=['This *means* that parsing can proceed in two steps: first, \n',
'the block structure of the document can be discerned; \n',
'second, text lines inside paragraphs, headings, and \n',
'other block constructs can be parsed for inline structure. \n',
'The second step requires information about link \n',
'reference definitions that will be available only at \n',
'the end of the first step. Note that the first step \n',
'requires processing lines in sequence, but the second \n',
'can be parallelized, since the inline parsing of one \n',
'block element does not affect the inline parsing of \n',
'any other.\n'])]@classmethods
Python offers classmethods via the @classmethod decorator.
The important thing to notice is that they receive explicitly a class as their first argument (in the same vein as how the instance methods receive explicitly an instance as a first argument). The convention is to use the name cls for the class instead of self.
A typical use case for classmethods are named constructors. It makes total sense, becase we want to create an instance of some class. Seems right to me to use the class as a receiver of the message to create an instance of itself, right? Who else could it be? Also, this is crucial when combined with inheritance.
Lists
Lists have more structure than headings, but they are recognized because each item in the list starts with * (at least in our subset of markdown).
Again, its the block responsability to identify if it is a list:
_IS_LIST = re.compile(r'^\*')
class Block:
# ...
def is_list(self):
return _IS_LIST.match(self.contents[0])If we also define the correspoinding element class List and put everything else in a paragraph class P, the parse function is becomes:
def parse(blks):
for blk in blks:
if blk.is_h():
yield H.from_block(blk)
elif blk.is_list():
yield List.from_block(blk)
else:
yield P.from_block(blk)The name constructor trick allows us to add a little bit more structure to the mix.
First, we define a Text element that will hold all the plain text. With that, we can define the new List and P elements, and redefine our H element. We also need an Item element for the list items.
class Text:
def __init__(self, text):
self.text = text
def __repr__(self):
return f'{self._name}(text="{self.text}")'
@property
def _name(self):
return self.__class__.__name__
class H:
def __init__(self, level, text):
self.level = level
self.text = text
def __repr__(self):
return f'H(level={self.level}, text={self.text})'
@classmethod
def from_block(cls, blk):
contents = blk.contents[0]
m = _IS_H.match(contents)
if not m:
raise ValueError(f'Block {blk} is not a valid H block')
_, end = m.span()
text = contents[end:-1].strip()
text = Text(text=text)
return cls(level=end, text=text)
class Item(Text):
pass
class List:
def __init__(self, items):
self.items = items
def __repr__(self):
return f'List(items={self.items})'
@classmethod
def from_block(cls, blk):
assert all(item[0] == '*' for item in blk.contents), "Invalid list"
items = [item[1:].strip() for item in blk.contents]
items = [Item(text=item) for item in items]
return cls(items=items)
class P:
def __init__(self, text):
self.text = text
def __repr__(self):
return f'P(text={self.text})'
@classmethod
def from_block(cls, blk):
text = Text(text=' '.join(line.strip() for line in blk.contents))
return cls(text=text)We add the Html and Body elements that any HTML documents has, but that don’t have any respresentation in markdown.
class Html:
def __init__(self, body):
self.body = body
def __repr__(self):
return f'Html(body={self.body})'
class Body:
def __init__(self, contents):
self.contents = contents
def __repr__(self):
return f'Body(contents={self.contents})'With the complete set of elements we can define a proper parse function, that, given a sequence of tokens (our Blocks), return a proper AST:
def _parse(blks):
for blk in blks:
if blk.is_h():
yield H.from_block(blk)
elif blk.is_list():
yield List.from_block(blk)
else:
yield P.from_block(blk)
def parse(blks):
contents = _parse(blks)
contents = list(contents)
body = Body(contents=contents)
return Html(body=body)We adjust our glue to_html function
def to_html(source, writer):
lns = lines(source)
blks = blocks(lns)
html = parse(blks)
writer.write(pprint.pformat(html))and m returns us a string representing the deeply nested and structured html document (indented here for readability):
Html(body=
Body(contents=[
H(level=1, text=Text(text="Python intro (2n part)")),
P(text=Text(text="The furture goes trhought making web pages.")),
P(text=Text(text="We need tooling.")),
H(level=2, text=Text(text="Dev environment")),
P(text=Text(text="We development tools:")),
List(items=[
Item(text="editor (you guessed it)"),
Item(text="life reloading")
]),
P(text=Text(text="With TDD: tmux driven devlopment.")),
H(level=3, text=Text(text="Markdown")),
P(text=Text(text="This *means* that parsing can proceed in two steps: first, the block structure of the document can be discerned; second, text lines inside paragraphs, headings, and other block constructs can be parsed for inline structure. The second step requires information about link reference definitions that will be available only at the end of the first step. Note that the first step requires processing lines in sequence, but the second can be parallelized, since the inline parsing of one block element does not affect the inline parsing of any other."))
])
)At this point we’ve converted our markdown document to a deeply nested data structure. It is a tree. It mimicks the DOM tree of an html document.
Ironically, an html document travels over the wire as a string that represents the document. It is the browser’s job to parse it (again!) and convert it to an actual DOM tree that it knows how to display on the screen.
We need to stringify it back!
Printing objects
Actually we’ve already did that. We’ve converted our tree to an string representation that I actually used in the last code snippet.
In that representation we’ve used the fact that we’ve overrided the __repr__ mehtod of the root node of our tree (the Html node). Remember:
writer.write(pprint.pformat(html))is calling __repr__ recursively under the covers. The f-expression in the Html.__repr__ method
return f'Html(body={self.body}'is asking the python interpreter to tell self.body to give it a string representation, which under the covers will call Body.__repr__ where there’s another f-expression:
return f'Body(contents={self.contents})'that is asking one of the python builtin types (list) to represent itself. The default implementation here is also recursive and prints an initial [ and then asks any object in the list to represent itself and when there are no more items left, it prints a closing ]. Any item itself is asked to be represented as string via its own __repr__ method.
That is why we get all the nested tree representation. It has been very smart from our part, right?
This is very typical in languages that have an interactive REPL. They need some sort of string representation to print and read the objects and the smart thing is to at least have a representation that is the same to read the objects and to print them.
But now we can no longer leverage on regexes or interpreter’s tricks. We have to do some work and serialize the parse tree into a string that actually is a valid html string.
Luckily, the job of having a tree-like data structure and having to print it, has been done so many times that people abstracted a pattern.
The visitor pattern
The vistor design pattern emerges when you have a data structure and want to walk it down and apply some algorithm on it. Here, we want to apply the algoritm that transforms it to a very specific string representation, a representation that is different from the one we obtain with the __repr__ trick.
Conventionally, the visitor pattern relies in having two categories of objects
- the Elements, which are the objects that conform the data structure
- the Visitor, which represents the special kind of algorithm you want to apply to the data
Here, our Elements are all the classes that we’ve used to represent html. And our visitor HtmlVisitor will be the object responsible to represent this tree to an html string.
This is a pattern on which those two classes collaborate and as such there is some coupling within them. The contract is very generic, tough:
- the Element provides and accept public method that (well) accepts a visitor
- the Visitor provides a method visit_* for any element that it visits
Altough it is not necessary in Python, we create an abstract Element class that makes the contract explicit
import abc
class Element(abc.ABC):
@abc.abstractmethod
def accept(self, visitor):
passWe use the abc.ABC base class for our Element and apply the abstractmethod decorator to the accept method. The metaclass of the abc.ABC ensures that subclasses of Element implement the accept method. If they don’t, it raises an exception.
This will not prevent us from forgetting the accept method before actually running the code. Python is not a statically typed language. But will give us a nice and informative runtime error the earliest as possible:
>>> class Foo(Element):
... pass
...
>>> foo = Foo()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class Foo with abstract methods acceptWe will now enforce the contract. We need to
- make any element inherit from Element
- implement the accept method in all of them
The concrete implementations in any element will be in charge of calling back the visitor for the specific method appropriate for them.
class Html(Element):
# ...
def accept(self, visitor):
visitor.visit_html(self)
class Body(Element):
# ...
def accept(self, visitor):
visitor.visit_body(self)
class Text(Element):
# ...
def accept(self, visitor):
visitor.visit_text(self)
class H(Element):
# ...
def accept(self, visitor):
visitor.visit_h(self)
class Item(Text):
def accept(self, visitor):
visitor.visit_item(self)
class List(Element):
# ...
def accept(self, visitor):
visitor.visit_list(self)
class P(Element):
# ...
def accept(self, visitor):
visitor.visit_p(self)Now we should implement the corresponding visit methods on the HtmlVisitor. Each method specializes to render the corresponding element:
class HtmlVisitor:
def __init__(self, writer):
self.writer = writer
def _emit(self, text):
self.writer.write(text)
def visit_html(self, html):
self._emit('<html>')
html.body.accept(self)
self._emit('</html>')
def visit_body(self, body):
self._emit('<body>')
for element in body.contents:
element.accept(self)
self._emit('</body>')
def visit_text(self, text):
self._emit(text.text)
def visit_h(self, h):
self._emit(f'<h{h.level}>')
h.text.accept(self)
self._emit(f'</h{h.level}>')
def visit_item(self, item):
self._emit('<li>')
self._emit(item.text)
self._emit('</li>')
def visit_list(self, lst):
self._emit('<ul>')
for item in lst.items:
item.accept(self)
self._emit('</ul>')
def visit_p(self, p):
self._emit('<p>')
p.text.accept(self)
self._emit('</p>')We just need to create a visitor an trigger the visiting process by making the root accepts it
def to_html(source, writer):
lns = lines(source)
blks = blocks(lns)
html = parse(blks)
visitor = HtmlVisitor(writer=writer)
html.accept(visitor)With that in place, the source.md text is converted to (indented for clarity):
<html>
<body>
<h1>Python intro (2n part)</h1>
<p>The furture goes trhought making web pages.</p>
<p>We need tooling.</p>
<h2>Dev environment</h2>
<p>We development tools:</p>
<ul>
<li>editor (you guessed it)</li>
<li>life reloading</li>
</ul>
<p>With TDD: tmux driven devlopment.</p>
<h3>Markdown</h3>
<p>This *means* that parsing can proceed in two steps: first, the block structure of the document can be discerned; second, text lines inside paragraphs, headings, and other block constructs can be parsed for inline structure. The second step requires information about link reference definitions that will be available only at the end of the first step. Note that the first step requires processing lines in sequence, but the second can be parallelized, since the inline parsing of one block element does not affect the inline parsing of any other.</p>
</body>
</html>A (partial) sequence diagram shows us how this little contract is actually triggering a huge amount of collaboration between all the objects

It is a good pattern to know.
Exploiting the visitor
Recovering the AST representation is easy with another visitor
class ReprVisitor:
def __init__(self, writer):
self.writer = writer
def visit_html(self, html):
self.writer.write(repr(html))but leveraging all the work to the builtin __rep__ that was already working. This seems silly, but the calling site will behave the same with any of the visitors
def to_python(source, writer):
lns = lines(source)
blks = blocks(lns)
html = parse(blks)
visitor = ReprVisitor(writer=writer)
html.accept(visitor)In a context where the actual visitor can be choosen in runtime, having a common interface makes total sense.
But, better than that, now we’ve opened the door to many funny things. And they require minimal effort. Look:
class ScreamingVisitor(HtmlVisitor):
def visit_text(self, text):
self._emit(text.text.upper())will produce a very noisy document.
And, drawing inspiration from Acme::HOIGAN, we can implement the funny HoiganVisior
import random
class HoiganVisitor(HtmlVisitor):
def visit_text(self, text):
oigans = [random.choice([
'OIGAN!',
'OYGA!',
'HOIGAN!',
'HOYGAN!']) for _ in text.text.split()]
self._emit(' '.join(oigans))and obtain this nice and usefull web page.
Homework
This is not a complete markdown parser, but is fun to see what 250 LOC can do. Some things left that should be easy (because they don’t need anything outside their blocks) are:
- bold text
- text in italics
- ordered lists
- code snippets
The full code for this post is here.